Overview
- The world's approximately 7,000 living languages are classified into several hundred families, of which six account for the vast majority of speakers: Indo-European, Sino-Tibetan, Niger-Congo, Afroasiatic, Austronesian, and Dravidian, each tracing back to a reconstructed proto-language spoken thousands of years ago.
- The comparative method, formalized in the nineteenth century for Indo-European, remains the gold standard for establishing language relationships by identifying systematic sound correspondences between related languages and reconstructing ancestral forms, though its reliable reach is limited to roughly 8,000–10,000 years.
- Computational phylogenetic methods borrowed from evolutionary biology have transformed historical linguistics since the early 2000s, producing dated language trees that converge with archaeological and ancient DNA evidence to illuminate the timing and routes of prehistoric human migrations across every inhabited continent.
The roughly 7,000 languages spoken in the world today are not randomly distributed across the globe, nor are they independent inventions. The vast majority can be grouped into families whose members descend from a common ancestral language, or proto-language, through millennia of gradual divergence. Historical linguists have identified several hundred such families, ranging from enormous groupings like Indo-European, with more than three billion speakers spread from Iceland to Bangladesh, to tiny families represented by a handful of communities in a single river valley.1, 13 The methods used to establish these relationships and to reconstruct the languages from which modern families descend constitute one of the most rigorous empirical programs in the humanities, and in recent decades, computational techniques borrowed from evolutionary biology have added new dimensions of quantitative precision. Together, linguistic reconstruction and phylogenetic modeling illuminate not only the history of languages themselves but the migrations, technologies, and social structures of the peoples who spoke them.2, 17
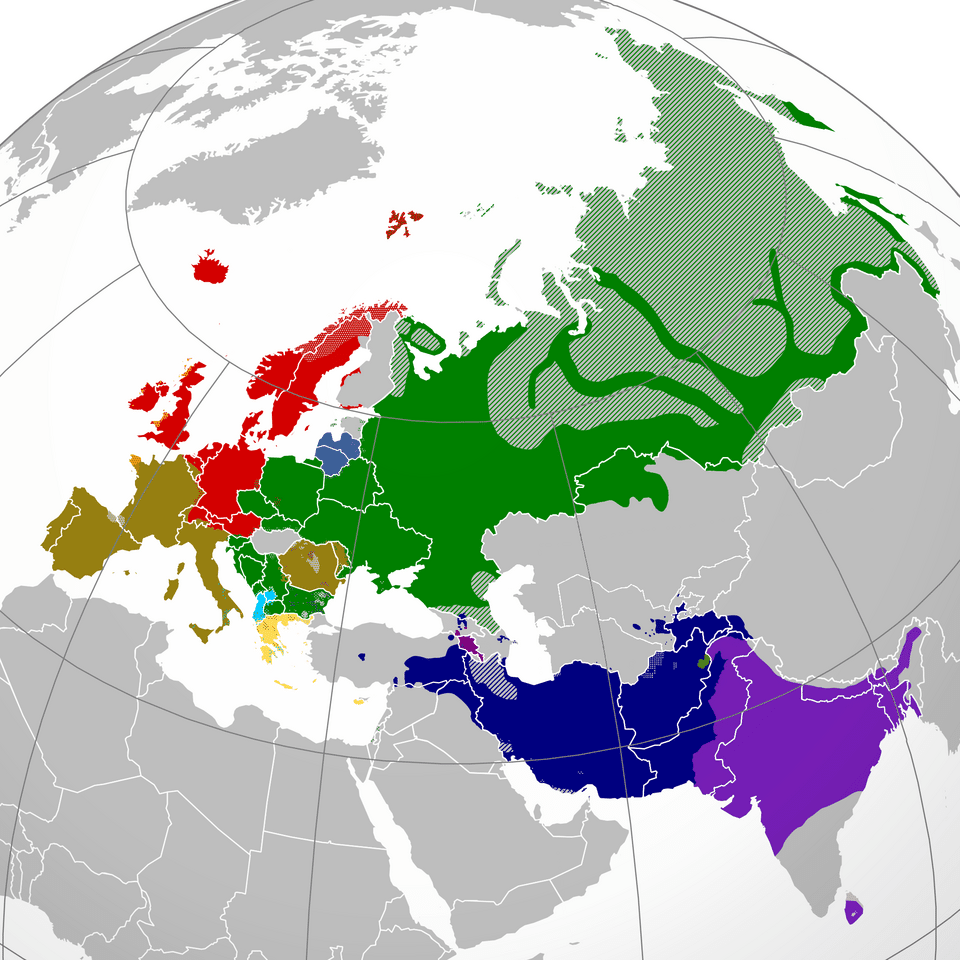
The world's major language families
A language family is a group of languages that can be shown, through systematic comparison, to have descended from a single common ancestor. The classification of the world's languages into families is one of the foundational achievements of modern linguistics, beginning with the recognition in the eighteenth century that Sanskrit, Greek, Latin, and Persian shared structural and lexical similarities too regular to be coincidental.1 Today, the largest families by speaker count are well established, though the internal structure of some and the relationships among them remain subjects of active research.
{kind=link}
Indo-European is the best-studied language family and the largest by number of speakers, encompassing approximately 3.3 billion first- and second-language speakers across some 449 languages. Its branches include the Germanic (English, German, Dutch, Scandinavian), Romance (Spanish, French, Italian, Portuguese, Romanian), Slavic (Russian, Polish, Czech, Serbian), Indo-Aryan (Hindi, Bengali, Urdu, Punjabi), Iranian (Persian, Kurdish, Pashto), Celtic, Armenian, Albanian, and the extinct Anatolian and Tocharian branches.13 The reconstructed ancestor, Proto-Indo-European, is the most detailed proto-language in existence, with thousands of reconstructed roots, an elaborate system of ablaut vowel alternations, and a rich morphological paradigm.1
Sino-Tibetan is the second-largest family by speakers, with approximately 1.4 billion, and includes the Sinitic branch (Mandarin, Cantonese, Wu, and other Chinese varieties) alongside the Tibeto-Burman branch (Tibetan, Burmese, and hundreds of smaller languages across the Himalayan belt and Southeast Asia). Phylogenetic analyses published in 2019 place the origin of the family in northern China approximately 5,900 to 7,200 years ago, broadly contemporary with the Yangshao and Cishan Neolithic cultures of the Yellow River basin.6, 7
Niger-Congo is the largest family by number of constituent languages, with more than 1,500 languages spoken across sub-Saharan Africa. Its best-known branch, Bantu, encompasses over 500 languages and traces to an expansion out of the Nigeria-Cameroon borderlands that began roughly 5,000 years ago and eventually reached southern and eastern Africa.8, 9 Afroasiatic spans North Africa, the Horn of Africa, and the Middle East, comprising some 375 languages including Arabic, Hebrew, Amharic, Hausa, and Berber; its branches are Semitic, Cushitic, Chadic, Berber, Omotic, and Egyptian, the last represented only by the now-extinct language preserved in hieroglyphic and Coptic texts. The Proto-Afroasiatic homeland remains debated, with proposals centering on the Horn of Africa or the eastern Sahara.11, 12
Austronesian is the most geographically expansive family, extending from Madagascar off the coast of Africa to Easter Island in the eastern Pacific, with more than 1,200 languages. Phylogenetic analyses consistently place its origin in Taiwan approximately 5,200 years ago, from which speakers dispersed through the Philippines, Indonesia, and Oceania in a series of expansion pulses linked to advances in outrigger canoe technology and horticulture.10, 19 Other major families include Dravidian (86 languages in South India and Sri Lanka), Turkic (41 languages across Central Asia and Anatolia), Uralic (Finnish, Hungarian, Estonian, and Sami), and Pama-Nyungan, which covers approximately ninety percent of the Australian mainland.13, 24
Major language families by approximate speaker count and geographic range13
| Family | Languages | Speakers | Primary geographic range | Estimated time depth |
|---|---|---|---|---|
| Indo-European | ~449 | ~3.3 billion | Europe, South & Central Asia, Americas | ~8,000–9,500 yrs |
| Sino-Tibetan | ~459 | ~1.4 billion | East & Southeast Asia | ~5,900–7,200 yrs |
| Niger-Congo | ~1,540 | ~700 million | Sub-Saharan Africa | Not firmly dated |
| Afroasiatic | ~375 | ~500 million | North Africa, Horn, Middle East | ~12,000–18,000 yrs |
| Austronesian | ~1,250 | ~350 million | Southeast Asia, Pacific, Madagascar | ~5,200 yrs |
| Dravidian | ~86 | ~220 million | South India, Sri Lanka | ~4,500 yrs |
| Turkic | ~41 | ~170 million | Central Asia, Anatolia | ~2,000–2,500 yrs |
Beyond these large families, dozens of smaller ones exist, alongside a number of language isolates — languages with no demonstrated genetic relationship to any other known language. Basque, spoken in the western Pyrenees, is the most famous European isolate; others include Ainu in Japan and several isolates in the Americas and Papua New Guinea. The extinct Sumerian language of ancient Mesopotamia is likewise an isolate, despite being one of the earliest written languages in the world.1, 13
The comparative method
The comparative method is the principal tool of historical linguistics for establishing language relationships and reconstructing proto-languages.

{kind=link}
It was developed in the early nineteenth century by scholars such as Rasmus Rask, Jacob Grimm, Franz Bopp, and August Schleicher, who recognized that systematic sound correspondences between the vocabularies and grammatical systems of Sanskrit, Greek, Latin, Gothic, and other Indo-European languages could only be explained by descent from a common ancestor.1
The method proceeds by assembling cognates — words in different languages that have descended from the same ancestral word — and identifying regular phonological correspondences among them. A classic example involves the word for "father": Sanskrit pitā, Greek patēr, Latin pater, Old English fæder, and Gothic fadar. The initial consonant alternation between p in Sanskrit, Greek, and Latin and f in the Germanic languages is not an isolated instance but appears in scores of cognate sets, reflecting a systematic sound shift described by Grimm's Law.1 Where such correspondences are regular and recurrent across numerous vocabulary items and grammatical morphemes, common ancestry is the most parsimonious explanation, and the ancestral sound can be reconstructed with a high degree of confidence. Reconstructed forms are conventionally marked with an asterisk, as in Proto-Indo-European *ph₂tér for "father."1
The comparative method also extends beyond phonology to morphological paradigms, syntactic patterns, and shared irregularities. Shared irregularities are considered particularly compelling evidence of common ancestry because they are unlikely to have arisen independently in unrelated languages. The common comparative method has been applied successfully to families on every inhabited continent, producing detailed proto-language reconstructions for families including Proto-Austronesian, Proto-Bantu, Proto-Uralic, Proto-Dravidian, and Proto-Algonquian, among many others.1, 19
Internal reconstruction and other methods
Internal reconstruction complements the comparative method by working within a single language rather than across related languages. It exploits morphophonemic alternations — cases where a single morpheme has different phonological forms in different grammatical contexts — to infer earlier stages of the language. For example, if a language shows alternation between [k] and [s] before different vowels in related word forms, the analyst can reconstruct an earlier stage in which only one of these sounds existed, the other having arisen through a conditioned sound change. Internal reconstruction is particularly valuable for language isolates, where no sister languages exist to permit comparative analysis, and for reconstructing stages older than the proto-language recoverable by the comparative method.1
Glottochronology, developed by Morris Swadesh in the 1950s, represents an early attempt to quantify the rate of language change and thereby date linguistic divergences. Swadesh proposed that a core vocabulary of culturally stable meanings (body parts, numerals, pronouns, basic natural phenomena) is replaced at a roughly constant rate across all languages, analogous to radioactive decay, and compiled a diagnostic list of 100 to 200 such meanings.14 By calculating the percentage of shared cognates between two related languages, one could in principle estimate the time since their divergence. The method generated considerable excitement in the 1950s and 1960s but fell into disrepute as empirical tests revealed that the assumed constant rate of replacement does not hold: Icelandic, for instance, has retained far more of its Old Norse vocabulary than Norwegian has, despite both having diverged from the same source approximately one thousand years ago.1, 14 Though classical glottochronology is now largely abandoned, it laid the conceptual groundwork for more sophisticated computational approaches that model variable rates of change.
Language contact presents a fundamental challenge to all methods of reconstruction. When speakers of different languages interact over extended periods, they borrow vocabulary, phonological features, and even grammatical structures from one another, potentially obscuring genetic relationships. Thomason and Kaufman documented in detail how intensive contact can produce wholesale restructuring of a language's grammar, not merely its vocabulary, in a process that blurs the boundaries between inherited and borrowed material.22 Distinguishing borrowed from inherited features is therefore a critical preliminary step before reconstruction can proceed, and failure to do so can lead to spurious groupings or missed connections.
Computational phylogenetics in linguistics
Beginning in the early 2000s, computational methods developed in evolutionary biology were adapted for historical linguistics, transforming a largely qualitative discipline into one capable of testing hypotheses with statistical rigor. The pioneering study was published in 2003 by Russell Gray and Quentin Atkinson, who applied Bayesian phylogenetic inference to a matrix of 87 Indo-European languages scored for 2,449 lexical cognate sets. Their analysis produced a dated phylogeny estimating that the Indo-European family began diverging approximately 8,700 to 9,800 years ago, a result consistent with the Anatolian hypothesis linking Proto-Indo-European to the spread of agriculture from Anatolia.2
Bayesian phylogenetic methods model language evolution as a branching process in which cognates are gained and lost along the branches of a tree, with the rate of change allowed to vary across different branches and different vocabulary items. This relaxed-clock approach addressed the central criticism of classical glottochronology: the assumption of a constant rate. By calibrating the analysis with historically attested dates of language divergence (for example, the date at which Latin literary records begin to diverge into distinct Romance varieties), the methods produce posterior probability distributions for divergence times throughout the tree.2, 17 A subsequent phylogeographic analysis by Bouckaert and colleagues in 2012 extended this framework by modeling the spatial diffusion of Indo-European languages across the continent, again finding decisive support for an Anatolian origin approximately 8,000 to 9,500 years ago.3
An earlier computational approach by Ringe, Warnow, and Taylor in 2002 took a different tack, applying perfect-phylogeny algorithms from computer science to a dataset of 24 Indo-European languages scored for phonological, morphological, and lexical characters. Their analysis confirmed the early separation of the Anatolian branch and provided computational support for several traditional subgroupings, while also identifying borrowing events that complicated the tree structure.17 The convergence of results from different computational methods and different datasets has substantially increased confidence in the major features of the Indo-European family tree, even as the question of the ultimate homeland remains debated.
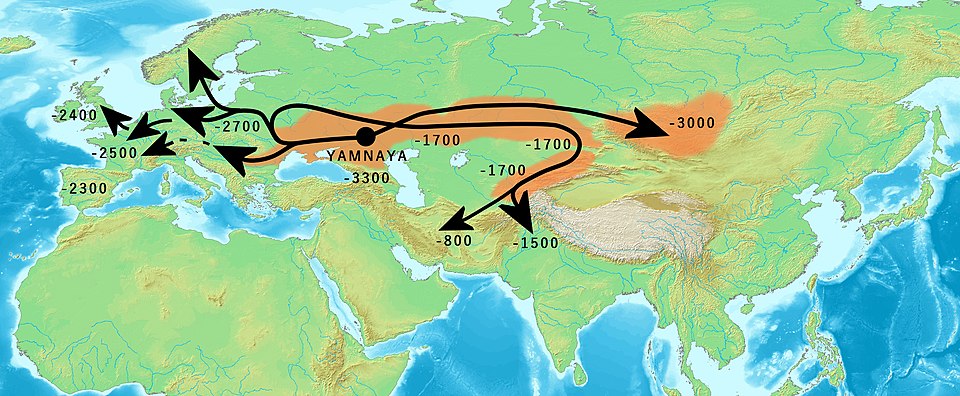
The most comprehensive phylogenetic analysis of Indo-European to date was published by Heggarty and colleagues in 2023, who analyzed 109 modern and 52 time-calibrated historical languages using ancestry-enabled Bayesian models that allowed ancient attested languages (such as Vedic Sanskrit and Classical Latin) to occupy positions as potential ancestors rather than only as terminal branches. The resulting tree supported a deep root approximately 8,120 years ago, south of the Caucasus in or near the northern Fertile Crescent, with a subsequent northward migration into the Pontic-Caspian steppe — a "hybrid" hypothesis that reconciles linguistic evidence with ancient DNA data showing massive Yamnaya-related migration into Europe around 4,500 years ago.4, 5
Diversification timelines and migration
Computational phylogenetics has now been applied to language families across the globe, producing dated trees that converge in illuminating ways with independent evidence from archaeology and population genetics. The resulting diversification timelines reveal that the major language families visible today are overwhelmingly products of expansions driven by innovations in subsistence — particularly agriculture and pastoralism — within the last 10,000 years.2, 10
{kind=link}
The Austronesian expansion provides one of the clearest demonstrations of convergence between linguistic and archaeological evidence. Gray, Drummond, and Greenhill applied Bayesian methods to lexical data from 400 Austronesian languages and produced a dated phylogeny placing the family's origin in Taiwan approximately 5,230 years ago. The tree revealed a distinctive pattern of expansion pulses interspersed with settlement pauses: rapid diversification during dispersal phases and slower change during consolidation periods. The pulse out of Taiwan into the Philippines occurred around 4,000 years ago, followed by a pause before further expansion through Island Southeast Asia and then into the open Pacific.10 This pattern matches the archaeological record of Lapita cultural complex expansion through Near Oceania and into Remote Oceania, and has been corroborated by independent analyses showing high congruence between phylogenetic estimates and traditional linguistic subgroupings.23
The Bantu expansion across sub-Saharan Africa has similarly been illuminated by phylogenetic methods. Grollemund and colleagues analyzed basic vocabulary from 424 Bantu languages and reconstructed an expansion originating in the Nigeria-Cameroon borderlands, progressing slowly through the Congo rainforest along savanna corridors before accelerating across the open savannas of eastern and southern Africa. The analysis showed that migration through unfamiliar rainforest habitat was delayed by an average of approximately 300 years compared with equivalent movements across savanna, demonstrating that ecological barriers shaped the pace and route of human dispersal.9
For Sino-Tibetan, two competing phylogenetic studies published in 2019 agreed on a northern Chinese origin but differed on the precise time depth. Zhang and colleagues, analyzing 109 languages, estimated a divergence approximately 4,200 to 7,800 years ago and placed the homeland in the Yellow River basin, associating the initial expansion with Yangshao and Majiayao Neolithic cultures.6 Sagart and colleagues, using a different dataset of 50 languages and 949 lexical root-meanings, obtained a somewhat older estimate of approximately 7,200 years and linked the family's origin specifically to north Chinese millet farmers of the late Cishan culture.7 Both analyses support the farming-language dispersal hypothesis, which posits that the adoption of agriculture creates demographic advantages that drive the expansion of farming populations and their languages into territories previously occupied by hunter-gatherers.6, 7
For Afroasiatic, a Bayesian phylogenetic analysis of the Semitic branch by Kitchen and colleagues estimated its diversification to approximately 5,750 years ago, placing the ancestor of all Semitic languages in the Near East during the Early Bronze Age, after having diverged from the broader Afroasiatic family in Africa.12 The deep structure and time depth of Afroasiatic as a whole remain contested, with estimates ranging from 12,000 to 18,000 years, near or beyond the practical limits of the comparative method.11
Estimated diversification ages of major language families2, 6, 10, 12
Rates of lexical evolution and deep ancestry
A key insight from computational phylogenetics has been the discovery that the rate at which words are replaced in a language is not uniform across the vocabulary but is strongly predicted by the frequency of everyday use. Pagel, Atkinson, and Meade demonstrated in 2007 that among more than 100 Indo-European languages, the most frequently used words — pronouns, numerals, and basic function words — evolve far more slowly than less common vocabulary. The word for "two," for example, has remained recognizably cognate across all Indo-European languages for roughly 8,000 years, whereas the word for "tail" has been replaced so frequently that unrelated forms appear even in closely related languages.15 This frequency-stability relationship follows a power law and appears to be a general property of lexical evolution rather than an accident of Indo-European history.
Building on this insight, Pagel and colleagues proposed in 2013 that certain "ultraconserved" words — those used with the highest frequency in daily speech — might retain cognate forms over much longer periods than the 8,000 to 10,000 years generally considered the outer limit of the comparative method. Using statistical models calibrated to the frequency-stability relationship, they identified a set of words (including pronouns such as "I," "we," and "this," and adverbs such as "not" and "what") that appear to preserve cognate forms across seven Eurasian language families (Indo-European, Uralic, Altaic, Chukchi-Kamchatkan, Dravidian, Kartvelian, and Inuit-Yupik) over a time depth of approximately 15,000 years.16 This proposal remains controversial; many historical linguists argue that the statistical methods do not adequately distinguish true deep cognates from chance resemblances, and that the proposed macro-family groupings have not been established by the comparative method.1 Nevertheless, the underlying finding that word frequency predicts replacement rate has been widely replicated and is now a standard element of computational models of language evolution.15
Patterns of linguistic diversity
The distribution of the world's languages across space is strikingly uneven, and the patterns of that unevenness encode information about deep human history. Johanna Nichols demonstrated in her landmark 1992 study that linguistic diversity — measured by the density and structural variety of language families per unit of geographic area — is far higher in certain "residual zones" (such as the Caucasus, New Guinea, and the Pacific Northwest coast of North America) than in the broad "spread zones" (such as the Eurasian steppe and the North African desert) through which individual language families have expanded to cover enormous territories.21
This pattern reflects the fundamental demographic asymmetry of human linguistic history. Language families expand when their speakers gain a demographic or technological advantage — typically through the adoption of agriculture or pastoralism — and replace or absorb the languages of smaller, less densely settled populations. The great spread-zone families visible today (Indo-European, Sino-Tibetan, Bantu, Austronesian) are all associated with agricultural expansions within the last 10,000 years.2, 9, 10 By contrast, in geographically fragmented or ecologically diverse regions where agriculture was difficult or arrived late — mountain ranges, archipelagos, dense tropical forests — older linguistic diversity persisted. Papua New Guinea alone hosts more than 800 languages belonging to dozens of families, many of them spoken by communities numbering in the hundreds, a reflection of tens of thousands of years of small-group isolation in mountainous terrain.13, 21
Computational phylogenetic analyses of grammatical traits have reinforced the picture of language families as products of cultural evolution shaped by lineage-specific historical processes rather than universal cognitive constraints. Dunn, Greenhill, Levinson, and Gray showed in 2011 that word-order correlations once thought to reflect universal properties of human cognition are in fact lineage-specific: the tendency for verb-object order to correlate with preposition use, for instance, holds within certain families but not across all of them, suggesting that cultural transmission and drift, not cognitive universals, are the primary determinants of grammatical structure.18
What reconstruction reveals about prehistory
The reconstruction of proto-languages yields far more than phonological systems and word lists; it provides a window into the material culture, environment, social organization, and belief systems of prehistoric peoples who left no written records. The principle is straightforward: if a word can be reconstructed for a proto-language, then the concept it denotes was known to the speakers of that language, even if those speakers lived millennia before the invention of writing.1
Proto-Indo-European, the most extensively reconstructed of all proto-languages, has yielded vocabulary for wheels and axles (*kwekwlo-, *h₂eḱs-), yoked draft animals (*yugom-), wool (*h₂wl̥h₁neh₂-), honey and mead (*medhu-), and a patrilineal kinship system with distinct terms for affinal and consanguineal relations. The presence of these terms constrains the dating and localization of the proto-language: if Proto-Indo-European speakers had words for wheeled vehicles, the language cannot predate the archaeological appearance of the wheel around 3500 BCE in the Pontic-Caspian steppe and Mesopotamia.1, 5 Similarly, the reconstructed vocabulary includes terms for horse (*h₁eḱwo-), domesticated cattle, and pastoral practices, which converges with ancient DNA evidence documenting the massive westward migration of Yamnaya steppe herders into Europe around 4,500 years ago.5
Proto-Austronesian reconstruction has illuminated the maritime culture of its speakers. Robert Blust's comprehensive reconstruction includes terms for outrigger canoe parts, sails, fishing techniques, rice cultivation, and tropical horticulture, consistent with the archaeological record of a Neolithic seafaring culture originating in Taiwan.19 Proto-Bantu reconstructions similarly include vocabulary for yam cultivation, iron smelting, and ceramic technology, aligning with the archaeological trace of the Bantu expansion through equatorial and southern Africa.8, 9
Linguistic paleontology — the inference of prehistoric culture from reconstructed vocabulary — must be applied with caution. Words can be borrowed across language boundaries, meanings can shift over time, and the absence of a reconstructed term does not necessarily mean the concept was unknown. Thomason and Kaufman's work on language contact demonstrated that intensive borrowing can introduce entire semantic domains from one language into another, and these borrowed terms may be mistaken for inherited vocabulary if comparative work is not sufficiently thorough.22 Despite these limitations, linguistic paleontology, when combined with archaeological and genetic evidence, remains one of the few methods available for accessing the cultural world of preliterate societies.
Convergence with genetics and archaeology
One of the most significant developments in the study of language families has been the growing convergence between linguistic phylogenies, archaeological chronologies, and population genetic data. The three disciplines now regularly produce corroborating evidence for the same prehistoric events, lending mutual support that would be impossible for any single discipline alone.
The most dramatic example is the Indo-European case. Ancient DNA analysis by Haak and colleagues in 2015 revealed that populations associated with the Yamnaya culture of the Pontic-Caspian steppe migrated massively into central Europe around 4,500 years ago, contributing approximately three-quarters of the ancestry of the Corded Ware culture. This genetic transformation aligns precisely with the spread of the non-Anatolian branches of Indo-European into northern and western Europe.5 The linguistic phylogenies, which consistently show the Anatolian branch as the first to diverge from the rest of the family, and the genetic data, which show that the Anatolian branch did not originate from the steppe, together point to a scenario in which Proto-Indo-European initially diversified south of the Caucasus before one branch moved northward onto the steppe and subsequently expanded westward into Europe and eastward into Central and South Asia.4, 5
The Austronesian expansion similarly finds corroboration across disciplines. The Austronesian Basic Vocabulary Database, compiled by Greenhill, Blust, and Gray, provides standardized wordlist data for more than 500 languages and has enabled systematic comparison between linguistic and genetic phylogenies.20 Genetic studies of Pacific Islander populations show patterns of successive founder effects — progressive loss of genetic diversity with increasing distance from Taiwan — that mirror the branching pattern of the linguistic tree, confirming that the Austronesian expansion involved actual population movements rather than mere language diffusion without demographic replacement.10, 23
The Bantu expansion provides a third case of convergence. Phylogenetic analyses of Bantu languages and genetic studies of sub-Saharan African populations independently trace a southward and eastward expansion from a West African origin, with the linguistic and genetic trees showing broadly similar branching patterns and timing.9 In each of these cases, the alignment of linguistic, genetic, and archaeological evidence greatly strengthens confidence in the reconstructed historical narrative, while discrepancies between the three lines of evidence highlight areas where further research is needed.
The application of computational phylogenetic methods to language data has thus accomplished two things simultaneously: it has placed historical linguistics on a more rigorous quantitative foundation, with explicit models and testable hypotheses, and it has integrated the study of language history into the broader enterprise of reconstructing human prehistory from multiple independent lines of evidence. Languages are not merely markers of ethnic identity or cultural affiliation; they are themselves evolving systems whose branching histories record the movements, contacts, and transformations of the human populations that carried them.2, 18, 21
References
Language trees with sampled ancestors support a hybrid model for the origin of Indo-European languages
Reconstructing Proto-Afroasiatic (Proto-Afrasian): Vowels, Tone, Consonants, and Vocabulary
Bayesian phylogenetic analysis of Semitic languages identifies an Early Bronze Age origin of Semitic in the Near East
Frequency of word-use predicts rates of lexical evolution throughout Indo-European history
How accurate and robust are the phylogenetic estimates of Austronesian language relationships?